
みなさんこんにちは、ZeroTerasu(@ZeroTerasu)です。
今回は、DataFrameのインデックスを列に変換する方法を解説します。
メソッド:df.reset_index(inplace=True)
参考コード
まずは、例として使用するデータフレームを作成します。
コード①:インデックス付きデータフレームの作成
import pandas as pd
import numpy as np
# index=np.array(['ind1','ind2','ind3'])
data={
'index':np.array(['ind1','ind2','ind3']),
'col1':np.array(['val1','val2','val3']),
'col2':np.array(['val4','val5','val6']),
'col3':np.array(['val7','val8','val9']),
}
df_sample = pd.DataFrame(
data=data,
)
df_sample.set_index('index', inplace=True)
df_sample実行結果:コード①
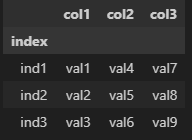
上記のように”index”というindex_labelを持ったdf_sampleという名称のデータフレームを作成しました。
次に、本記事の本題のdf_sampleのインデックスを列に変換します。
コード②:df_sampleのインデックスを配列に変換します
df_sample.reset_index(inplace=True)
df_sample実行結果:コード②
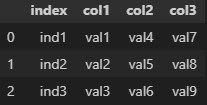
上記の通りindexが列に変換され、新たにインデックスが割り振られました。

コメント