
みなさんこんにちは、ZeroTerasu(@ZeroTerasu)です。
今回はPythonでデータ分析をする際に必須となるライブラリのPandasの基礎と使い方について解説していきます。
Pandasは、エクセルやGoogle Spreadsheetなどの表計算ソフトでの操作をコマンド操作で実行するためのPythonライブラリとイメージして頂くと分かりやすいかと思います。
表計算ソフトでは、GUI(Graphic User Interface)によって作業内容が即座に視覚的に把握できますが、Pandasを用いたデータ分析では、一定量のコードを記述した後にメソッドの実行をすることでようやく処理内容を視認することが出来ます。
そのため、慣れるまでは表計算ソフトの方が処理が早いと思われる方もいらっしゃるかと思いますが、慣れてくれば表計算ソフト以上に様々な処理が可能になりますので、この機会にマスター頂ければ幸いです。
この記事では、表計算ソフトでの処理をPandasで実行するための方法を解説するという角度からアプローチしていきます。
①Pandasのインストール
まずは、Pandasライブラリをインストールしましょう。Windowsの場合、Powershellやコマンドプロンプト、MACの場合ターミナル、Jupyterlabの場合はセルに「pip install pandas」と入力して実行します。
# Pandasのインストール方法
pip install pandas②Pandasのimport
ここから実際にPythonコードの記述を始めます。まずは、「import pandas as pd」を実行します。
使用例1:import ライブラリ名(モジュール名)
使用例2:import ライブラリ名(モジュール名) as ライブラリ(モジュール)省略名
使用例3:from ライブラリ名(モジュール名) import オブジェクト名
importは、pythonモジュール・パッケージ・ライブラリ(呼び方は様々ですが、ここではほぼ同義語と考えて頂いて大丈夫です。今回は「ライブラリ」と呼称します。)を、Pythonコード内で使用できるように呼び出すメソッドです。
また、「as 省略後」とすることで、以後は当該ライブラリを「省略後」(今回は、「pd」)で使用することが出来ます。
また、ライブラリには通常複数のクラスやメソッドが格納されています。その中から特定のクラスやメソッド(上記の「使用例3」の「オブジェクト名」に該当します。)だけを使用したい場合は、使用例3のように任意のものだけを参照することも可能です。
import pandas as pd③DataFrameメソッドを使用してテーブルを作成
次に、下記のエクセルのようなテーブルをPandasで作成してみます。
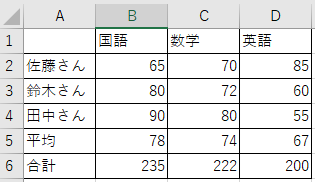
テーブルの作成には、Pandasライブラリの「DataFrame」というメソッドを使用します。
まずは、DataFrameメソッドについて解説します。
尚、リストや辞書型等のデータ形式については下記記事にて解説しておりますのでご参照下さい。
とは?使用例と違いの説明-160x90.jpg)
DataFrameメソッド
DataFrameの構成要素(パーツ)
DataFrameの行名と列名
DataFrameメソッドの引数
Pandasライブラリのメソッドである「DataFrame」は行と列で構成される2次元データ構造を扱う際によく使用されます。
DataFrameとは、行(Raw)と列(Column)とデータ(Data)から構成される表(テーブル)のことです。
まずは、DataFrameを構成する要素(パーツ)を確認します。
DataFrameは下記の画像のように行(Raw)、列(Column)、データから構成されます。
3つの要素から成るという点では非常にシンプルで分かりやすい構造になっています。

次に、各行(インデックス) と 各列(カラム)にはそれぞれ名前があるということについて説明します。
DataFrameを構成する各行(インデックス)および各列(カラム)にはそれぞれ名前があります。
下記画像での各行の名前および各列の名前は以下のようになります。
インデックス名=0,1,2
*この例では、インデックス名は数字になっていますが、文字列をインデックス名に指定することもできます。
カラム名=名前、国語、数学、英語

個別の行または列の情報を抽出したいときは、データフレームオブジェクトに対して任意のインデックス名またはカラム名を指定します。*DataFrameの使い方については後述致します。
次に、DataFrameメソッドの引数について説明します。
DataFrameメソッドには下記の引数が用意されています。
その中でも、「data」、「index」、「columns」は重要な要素となります。
pd.DataFrame(data, index, columns, dtype, copy)| 引数 | 内容 |
| data | ・DataFrameに格納するデータを指定する。
・対応形式=二次元リスト型、二次元NumPy配列、辞書型 ・入力方法=手入力、変数代入、JSON, CSV, EXCELファイルを直接読み込み。 |
| index | ・行名 |
| columns | ・列名 |
| dtype | ・列毎のデータ型を規定する。 |
| copy | ・引数としての「copy」を指定する機会はほとんどないと思います。「pd.DataFrame.copy()」とすることでコピー元のオブジェクトに変更を加えることが無くなります。 |
【重要】DataFrameのdata引数にデータを格納する方法
DataFrameの肝になるのが、引数dataへのデータの格納方法です。
今回は、①リストをdataに格納する方法と②numpy配列をdataに格納する方法と③seriesをdataに格納する方法をそれぞれ解説致します。
①-1 リストをdataに格納する方法(data=リスト、indexおよびcolumns=省略)
まずはリストからDataFrameを生成します。最初のサンプルでは、引数dataにリスト形式でデータを格納するだけのリストを使った最もシンプルな方法を紹介します。
引数indexおよび引数columnsは省略しています。その場合、それぞれは下記画像のように0から始まる連番となります。
import pandas as pd
df = pd.DataFrame(["A", "B", "C"])
# またはリストを変数に代入して以下のようにしても良いです。
list = ["A", "B", "C"]
df = pd.DataFrame(data=list)
df
#実行結果
0
0 A
1 B
2 C①-2 リストをdataに格納する方法(data=リスト, index=指定, columns=指定)
次に、data, index, columnsをそれぞれ指定する方法を説明します。
import pandas as pd
# 以下、data変数への代入までは参考情報。実際には、生成されたdataを使用して挙動確認頂いて結構です。
data_list = []
for i in range(0,9):
data_list.append('data' + str(i+1))
# data_list = ['data1', 'data2', 'data3', 'data4', 'data5', 'data6', 'data7', 'data8', 'data9']
def convert(data_list, colnum):
return [data_list[i : i+colnum] for i in range(0, len(data_list), colnum)]
data = convert(data_list,3)
# data = [['data1', 'data2', 'data3'], ['data4', 'data5', 'data6'], ['data7', 'data8', 'data9']]
# 上記は、2次元リスト配列の作成方法を参考程度に掲載しました。
# 本セクションの主題は、dataに上行の変数を代入して、以下の処理を実行するだけで確認出来ますので、変数作成方法は理解できなくても構いません。
index = ["row1", "row2", "row3"]
columns = ["col1", "col2", "col3"]
df = pd.DataFrame(data=data,
index=index,
columns=columns)
df
#実行結果
col1 col2 col3
row1 data1 data2 data3
row2 data4 data5 data6
row3 data7 data8 data9②-1 numpy.array 1次元配列をdataに格納する方法
次は、numpyを使用してDataFrameを作成します。
numpyとリストの違いは、別途解説記事を作成予定ですが、ざっくりと説明しますと、numpyの方が実行速度が速く、様々なメソッドが用意されているためデータ加工に有利です。但し、データ数が多くない場合は、python組み込み関数であるリストでも大差はありません。(numpyが効果を発揮するのは、大量データの処理の際です。)
下記のコードでは、引数dataに辞書型で代入しています。「キー:値」の値の部分にnumpy配列を用いています。
import pandas as pd
import numpy as np
data = {
'国語':np.array([65,80,90]),
'数学':np.array([70,72,80]),
'英語':np.array([85,60,55]),
}
df = pd.DataFrame(data)
df
#実行結果
国語 数学 英語
0 65 70 85
1 80 72 60
2 90 80 55②-1 numpy.array 2次元配列をdataに格納する方法
次に、2次元配列で引数dataにデータを格納します。
2次元配列でdataに格納する場合、indexおよびcolumnsは個別に変数に格納した方が分かりよいです。
import pandas as pd
import numpy as np
data = np.array([[65,80,90],
[70,72,80],
[85,60,55]])
index = ['佐藤さん', '鈴木さん', '田中さん']
columns = ['国語', '数学', '英語']
df = pd.DataFrame(data, index=index, columns=columns)
df
# 実行結果
国語 数学 英語
佐藤さん 65 80 90
鈴木さん 70 72 80
田中さん 85 60 55③ seriesをdataに格納する方法
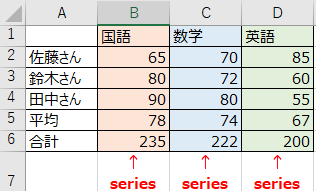
最後にseriesをdataに格納する方法について説明します。
seriesとは、エクセルでいうところの、1列分のデータに相当します。下記の画像の「国語」、「数学」、「英語」の各列をそれぞれseriesと言います。
seriesが集まって構成されたものをDataFrameと言います。
下記のコードでは、まず各seriesを作成し、その後DataFrameに統合する方法をとっています。
import pandas as pd
data = {
'国語':pd.Series([65,80,90,100]),
'数学':pd.Series([70,72,80]),
'英語':pd.Series([85,60,55]),
}
df = pd.DataFrame(data)
df
#実行結果
国語 数学 英語
0 65 70.0 85.0
1 80 72.0 60.0
2 90 80.0 55.0
3 100 NaN NaN上記の通り、Seriesを使った場合は、各Seriesの大きさが揃っていなくてもエラーになりません。
これが、Seriesを使用する一番のメリットになると思います。

コメント